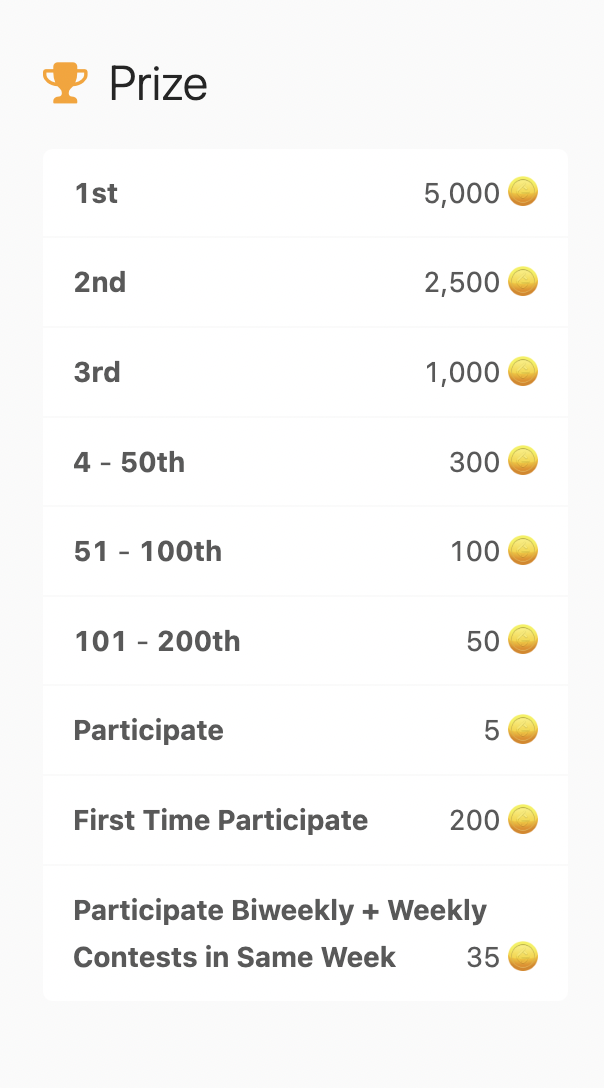
Gradio는 Model을 웹으로 손쉽게 사용할 수 있게 해주는 라이브러리이자 플랫폼입니다.
각종 UI를 쉽게 그릴 수 있게 해주고, input을 받아 서버에서 inference 혹은 predict를 한 후 그 결과를 사용자들에게 돌려줍니다.
다른 웹 어플리케이션 서버들과 차별화된 점은 ML 모델이 자주 다루는 컴포넌트들이 이미 이쁜 UI로 구현이 돼 있다는 점이죠.
복잡한 커스터마이징은 어렵지만, 오디오, 비디오, 챗봇, 이미지, 텍스트, 확률 표시 등 머신러닝에서 자주 사용하는 기능들을 거의 코딩 없이 제공가능합니다.
사용법
먼저 gradio를 설치해 줍니다.
pip install gradio
아래가 기본적인 템플릿입니다.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
이 템플릿을 실행 시켜보면 주소가 나오는데, 그 주소를 웹 브라우저에 복사 붙여넣기를 하면 다음과 같은 웹페이지가 뜹니다.
동작 방식
gradio는 기본적으로 fastapi를 기반으로 돌아갑니다.
복잡한 것들을 설명하기는 지면이 길어지니 주로 사용하는 예시들을 들어드리겠습니다.
12번째 줄은 함수가 들어갑니다. 정확히는 python의 callable이면 모두 들어갈 수 있습니다.
이에 대한 구체적인 구현은 4-7번째 줄에서 확인할 수 있습니다.
여기서 13번째 줄의 inputs 파라미터에는 어떤 종류를 넣을 것인지 결정할 수 있습니다.
여기서 inputs에 들어갈 수 있는 오브젝트들을 컴포넌트라고 합니다.
가장 기본적인 동작은 inference 함수의 parameter 명이 컴포넌트의 label 명이 됩니다.
즉 13번째 줄은 text 컴포넌트를 사용하겠다는 것이고, text의 label은 'my_input'이 됩니다.
조금더 자세히는 gr.components.Text 를 내부적으로 생성하게 되는데 자세한 설정을 하고 싶다면 이 컴포넌트를 직접 넘겨줘도 됩니다.
이왕이면 inference 함수의 parameter의 개수가 inputs의 개수가 일치하는게 좋습니다.
아래 예제를 보시면 더 이해가 쉽습니다.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
제가 예전에 담당했던 업무중에 사람 얼굴의 특징점 (눈, 코, 입 등이라고생각하면 편하다) 가지고 기능을 짜야했던 적이 있었습니다. 지금도 그렇지만 그때는 텐서감수성이 떨어질 때라서, 현재 짜고 있는 코드가 맞게 동작하는지 잘 이해가 안가는 경우가 굉장히 많았습니다. 🙂
이미지 출처: https://towardsdatascience.com/facial-keypoints-detection-deep-learning-737547f73515?gi=529af36da233
특히, 이게 단순 산술연산이 아니라 이미지상에서 어느 부분을 짜르거나, 어느 부분을 기준으로 뭔짓을 가해야하는 종류라면 정말 디버깅에 많은 시간이 걸립니다. (예를 들면 얼굴 부분만 자르기!)
짜도 그 이미지에 알맞게 적용됐는지, 머리속으로 상상은 해도 실제로 그렇게 짜졌는지 실행하기 전까지 불안에 떨어야 했죠.
따라서 디버깅 하면서 이미지를 보는 건 디버깅 시에 확실히 이점이 있습니다. 보면서 실수를 그때 그때 잡을 수 있으니까요. 특히 저 같은 뉴비 머신러닝러는 더더더더더더욱 그렇습니다.
이처럼 머신러닝, 특히 비전관련한 테스크를 하다보면 디버깅을 할 때 이미지 파일을 보면서 할 때 더편한 경우가 왕왕 있습니다.
대안들
중간중간 이미지를 보는 작업은 생각보다 편하지만, 단순하게 이미지를 로그처럼 찍는 방법은 생각보다 불편합니다. 이렇게 할 경우 폴더를 열어서 이미지를 켜봐야 하고, 코드에 삽입해서 작성함으로 그때 그때 모델을 실행해야하죠.
특히 후처리를 해야할 경우 매 실행마다 모델을 로드해야하기 때문에 더 오랜 시간이 걸리게 됩니다. 이것 때문에 코드하나 고치고 다시 재시작하고, 모델을 로드하는데 많은 시간을 소모하게 됩니다. 😢
다른 방법으로는 plt.show() 같은 짓을 코드에 삽입하는 겁니다. 그러면 scientific mode로 pycharm을 사용하면 되죠. 하지만 전 이 scientific mode를 좋아하지 않습니다. 솔직히 창도 번거롭게 많아지고 생각보다 기능이 불편했습니다. 제가 잘 사용하지 못하는걸까요.
플러그인
그래서 저는 주로 pycharm의 디버거를 사용하는데, 이 디버거에서 사용하기 매우 좋은 플로그인을 소개하고자 합니다.
GAN은 두가지 component로 구성되어 있습니다. Generator와 Discriminator입니다. Generator는 실제 데이터와 유사한 분포의 데이터를 생성하기 위해 노력하는 Component죠. Discriminator는 Generator가 만든 가짜 데이터와 실제 Data를 구별해주는 Component였습니다. Discriminator로 머신러닝 네트워크를 사용하는 이유는 generator가 생성하는 분포와 실제 데이터 분포를 수식화 하기 힘든 매우 어려운 분포이기 때문입니다.
GAN의 Sampling
그리고, GAN은 latent space에서 latent vector z를 sampling합니다. 초기의 latent space는 아무런 의미를 가지지 않기 때문에 여기서 sampling된 latent vector z도 아무런 의미를 가지지 않습니다만, 학습을 통해서 latent vector와 특정 데이터를 연결하게 되면서 latent space가 의미를 가지도록 바꿔줍니다. 마치 사람들이 아무의미없는 것들에 의미를 부여하는것처럼 네트워크도 경험적으로 latent space에 의미를 부여하기 시작할겁니다. ㅎㅎ
GAN의 학습 Algorithm
GAN의 학습은 2가지 step으로 이루어졌었죠. 첫번째 스텝에서는 Generator를 고정시키고, Discriminator를 학습시킵니다. 두번째 스텝에서는 Discriminator를 고정시키고, Generator를 학습시킵니다. 그리고 고정시킴에 따라 Loss Function이 일부 변경되었었습니다.
전체를 요약해보자면
GAN의 전체 구조를 요약해보자면 GAN은 latent space에서 sampling 한 z로부터 Generator는 어떠한 데이터 분포를 만듭니다. 그리고 이렇게 생성한 Generator의 분포와 실제 데이터 분포를 Discriminator로부터 비교하게 함으로서 G가 잘생성하면 D를 혼내주고, D가 잘 구분하면 G를 혼내주는 방법으로 학습을 수행합니다.
아래와같은 구조를 가지고 있죠.
GAN과 JS Divergence
직관적으로 GAN이 왜 동작하는지는 쉽게 이해가 됩니다. 그런데 직관적으로만 ㅇㅋ 하고 가면 조금 찝찝하죠. 그래서 GAN이 동작하는 이유에 대해서 증명을 하나하고 넘어가겠습니다.
이 내용은 이 후 WGAN으로 넘어가기 위해서 반드시 필요하다고 생각해서 넣었는데, 생략하시고 싶으시면 바로 WGAN으로 넘어가시면 됩니다.
한줄 요약
최초 제안된 GAN의 Loss function은 JSD를 계산하게 되는데, JSD는 두 분포가 겹치지 않았을 때, 상수 값을 가져서 gradient 계산으로 optimal을 찾는 것이 쉽지 않다.
GAN의 동작 조건
GAN의 목표는 실제 데이터 분포인 Pdata 와 Generator 가 만든 가짜 데이터 분포인 Pg 가 같아지는 것을 목표로 합니다.
즉 GAN의 Loss Function인 아래 식이 최적일 때, Pdata=Pg 임을 만족해야한다는 뜻이죠.
오우 정신 사납습니다. 결론은 저희의 Loss function은 JSD로 귀결되게 됩니다.
그리고 JSD는 두 분포사이의 거리로 사용할 수 있음으로, 따라서 위의 수식을 최소로 만드는 것은 두 분포사이의 거리를 최소로 만드는 것이란 거죠!
WGAN의 등장
자 이제부터 쉬워져요. 왜냐면 여기서 수학을 다뺏거든요.
한숨돌리시고 갑시다!
JS Divergence는 학습에 적합하지 않다!
WGAN에서 주장하길 좋은친구아저씨가 제안한 loss의 JSD는 학습에 적합하지 않다는 것이었습니다. 이걸 이해하기 위해서는 SUPP를 이해하셔야하는데, 간단히 설명할께요.
지지 집합 SUPP
SUPP는 support라고 읽는데, 한국어로는 지지집합이라고 합니다. 멋진 위키를 참고하자면
수학에서, 함수의 지지집합(支持集合, 영어: support 서포트[*]) 또는 받침은 그 함수가 0이 아닌 점들의 집합의 폐포이다.
X가 위상 공간이고, {\displaystyle f\colon X\to \mathbb {R} }이 함수라고 하자. 그렇다면 {\displaystyle f}의 지지집합 {\displaystyle \operatorname {supp} f}는 다음과 같다. {\displaystyle \operatorname {supp} f=\operatorname {cl} {x\in X\colon f(x)\neq 0}} 여기서 {\displaystyle \operatorname {cl} } 폐포 연산자다.
인데, 사실 어려운말 다 쳐내고, 이해하시면 좋은 것 단하나 바로 0이 아닌 점들의 집합 입니다. 콤펙트하고 머시기하고 유계 집합 머시기 이런것들이 있는데 사실 저도 잘모릅니다. 수학과가아니라서요. 개념상 0이 아닌 점들의 집합으로 이해하고 넘어가셔도 큰문제가 없습니다.
그림으로 표현해보겠습니다. 두 분포 \mathbb{P}_r 과 \mathbb{P}_g 가 있다고 하겠습니다. 그 분포가 아래와 같이 있다고 가정해볼께요.
여기서 SUPP \space \space \mathbb{P}_r 는 B 공간이 되고, SUPP \space \space \mathbb{P}_g 는 A공간이 된다는 겁니다. 그야말로 0이 아닌 점들의 집합입니다.
이 때, \mathbb{P}_r(A)=0, \mathbb{P}_r (B)=1 이 될 것입니다. 반대로, \mathbb{P}_g(A)=1, \mathbb{P}_g (B)=0 이 되겠죠?
분포의 거리 측정
자 그럼 조금더 직관적인 설명을 위해서, 두 확률 변수를 2차원상의 분포라고 가정해서 생각해보겠습니다.
두 분포가 겹치지 않는다는 사실은 명확하죠. 서로 0 과 \theta 사이에서만 움직이니까요.
여기서 \theta 는 다양한 값을 가질 수 있습니다.
하지만, \theta \neq0 인 경우를 제외한 어떤 경우에도 두 분포가 겹칠 수는 없습니다. 이 경우 두 분포 중 하나가 0이 아닌 값을 가질 때는 다른 분포에서는 무조건 0인 값을 가지게 될 것입니다.
가 된다는 것이죠. 따라서 마찬가지로 \theta 의 값과 상관없이 상항 같은 상수값을 나타내게됩니다.
GAN에서의 의미
이는 GAN을 학습하는데 큰 문제가 됩니다. Loss Function은 가까우면 가깝다고, 멀면 멀다고 명확히 말을 해주어야 이에 따른 gradient를 계산할 수 있습니다. 하지만 두 분포의 SUPP이 겹치지 않는다면 '두 분포가 완전히 다르다.' 라는 정보만 줄 뿐 어떻게 가깝게 만들지에 대한 정보 즉 gradient를 계산할 수 없다는 뜻입니다.
즉, D가 너무 깐깐하게 두 분포를 판단해서, 만약 두 분포가 겹치지 않는다면 두분포를 어떻게 가깝게 만들지에 대한 gradient를 계산할 수 없게 된다는 거죠.
이는 사실 일만적으로 이미지 생성과 같은 높은 dimension의 문제를 푸는 GAN에서는 이러한 분포가 겹치지 않는 문제가 더 심하게 발상할 것이기 때문에 GAN의 학습 성능이 떨어지는 등 꽤 크리티컬한 문제로 다가올 것이었습니다.
이 문제를 해결하러 왔다.
이 문제를 해결하기 위해서 2가지 방법을 소개해드리도록 하겠습니다.
분포를 건드리는 방법
분포의 거리 측정 방식을 개선하는 방법
당연히 우리가 앞으로 할 짓은 후자입니다만, 전자 쪽은 매우 간단하고 직관적으로 이해가 쉬우니까 한번 보고 가실께요.
노이즈를 통한 해결
Support가 겹치지 않는 것이 문제였습니다. 때문에 기존의 이미지에 노이즈 n을 추가해주면서 아래 그림처럼 두 분포의 Support영역을 넓혀 겹칠수 있도록 만들어주는 것입니다. 이렇게 두 분포를 겹치게 만들어주면 JSD를 사용해서 문제를 해결할 수 있습니다.
하지만 이러한 해결방법은 생성된 이미지가 굉장히 흐릿하게 나오는 등 문제가 발생하는 등 성능이 좋지 않게 나왔다고 합니다.
JSD가 아닌 다른 형태의 거리 측정 방식 사용
JSD는 두 분포가 겹치지 않을 때 상수가 나와 gradient를 계산하기 힘든 문제가 있었습니다.
따라서 저자는 분포가 겹치지 않아도 두 분포의 거리를 측정할 수 있는 방법인 Earth Mover Distance를 사용할 것을 제안합니다. 그리고 이제부터가 WGAN의 시작이죠.
WGAN은 다음 포스팅에서 다루도록 하겠습니다. 길이 너무 길어져서 여기서 한번 끊고 가도록 하겠습니다.
Reference
(Paper) Goodfellow, Ian J., et al. "Generative adversarial networks." arXiv preprint arXiv:1406.2661 (2014).
우리가수행할 수 있는 연산은 각 정수에다가 숫자들을 더하는 건데 예를 들면 123이 있다면 여기다가 4를 더해서 1234로만드는 이런연산이가능하다.
123 → 1234
이런 연산을 최소한으로 수행해서 strictly increasing order로 만들어라.
sample Input
4 3 100 7 10 2 10 10 3 4 19 1 3 1 2 3
Sample Output
Case #1: 4 Case #2: 1 Case #3: 2 Case #4: 0
설명:
첫번째는 아래처럼 추가하면 100, 700, 1000 으로 오름차순으로 만들수 있다.
100
7 → 700
10 → 1000
총 0을 4번 추가했고, 이거보다 적게 추가해서 오름차순으로 만들 수 없기 때문에 답은 4다
솔루션 코드
for tc inrange(int(input())):
N = int(input())
X = list(map(int, input().split(" ")))
ans = 0
for i inrange(1, N):
if X[i] > X[i-1]:
continue
s_b = list(str(X[i-1]))
s_p_max = list(str(X[i]))
s_p_min = list(str(X[i]))
count = 0
ori_len = len(s_p_max)
whileint("".join(s_b)) >= int("".join(s_p_max)):
s_p_max += "9"
s_p_min += "0"
count += 1
ans += count
ifint("".join(s_b)) < int("".join(s_p_min)):
X[i] = int("".join(s_p_min))
else:
# same
X[i] = X[i-1]+1
print(f"Case #{tc+1}: {ans}")
그지처럼 풀었다.
첫번째 원소는 건드리지 않아도 되니까 range(1, N) 으로 시작한다. 시작부터 크다면 신경쓸필요없으니까 그리고 뒤를 9로 일단 채워나가면서(그 자리수에서 체울 수 있는 가장 큰 수) 될때까지 자리수를 늘려나간다.
그리고 늘려나간 최종 값중에서 가장 작은 값 (예를들자면, 10에서 2개의 digit을 추가했다면, 1099이 최대값, 1000이 최솟값이 된다.)이 배열의 이전 값 (s_b, X[i-1]) 보다 크다면 그게 답이 되기 때문에 X[i]에 그 값 자체를 넣어준다. int("".join(s_p_min))
만약 최솟값이 같다면, X[i-1]의 값에 +1해주면 된다. 이부분은 +1해줌으로서 다른자리까지 전부 변화시켜주려면 9여야하는데, 모두 9로 되어있는 경우는 14번 째 줄의